Principles
Synthetic Data: Examples – Realistic – using AI (SYNDERAI), pronounced /ˈsɪn.də.raɪ/
© HL7 Europe | Main Contributor: Dr. Kai U. Heitmann | Privacy Policy • LGPL-3.0 license
Introduction
One of the recurring challenges in developing, testing, and validating HL7 FHIR-based systems is the availability of medically realistic, safe, and standards-compliant sets of example/test data. To address this, the xShare Project integrates synthetic data generated under this initiative, coordinated by HL7 Europe.
SYNDERAI provides synthetic, high-quality HL7 FHIR instances that replicate real-world clinical records without exposing personal health information. These instances are used across the xShare toolbox — from transformation to visualization to sharing — enabling fully privacy-compliant test workflows, aligned with the European Electronic Health Record Exchange Format (EEHRxF) and General Data Protection Regulation (GDPR, EU 2016/679) principles.
SYNDERAI Design
SYNDERAI datasets are designed to
- represent realistic clinical scenarios, including medications, allergies, problems, encounters, vital signs, depending on the covered use case,
- be conformant to HL7 FHIR Implementation Guides, including IPS, EU Laboratory Report, and Hospital Discharge Summary,
- use realistic but not real patient data, ensuring safety in both development and demonstration environments.
The project generates not just HL7 FHIR JSON instance files, but also includes metadata, test coverage indicators, and placeholders for multilingual expansion and narrative descriptions.
There is a SYNDERAI Synthetic Data Generation and Use Policy defined.
Within xShare, SYNDERAI synthetic data is
- used in architecture testbeds for download, share, and visualize flows, as seen at vi7eti.net,
- prepared to support Connectathon/Plugathon/Hackathons/Projectathon test cases, e.g. from IHE Europe
- embedded in documentation and walk-throughs as examples of valid HL7 FHIR structures and content.
This data enables xShare Adoption Sites and developers to
- run the Yellow Button tools without privacy concerns
- simulate end-to-end workflows with repeatable, traceable data
- demonstrate compliance with technical and legal requirements.
Major Achievements
Following the design, a couple of achievements were made: European patient cohorts and providers were compiled, assuring some realistic properties. Clinical "stories" were combined with the individuals to create use case based data sets that are subsequently turned into the appropriate example/testing instances. Add use of AI at any of these levels where appropriate, e.g. prompting for populating data fragments based on a given demographic and clinical context or to provide human readable text based on existing granular data.

Depositphotos.com © Robert Marmion
Patient cohorts, Provider crowds
Demographics
Large collections of synthetic human names residing in Europe with gender, language, birthdate and age, nationality, home address and geo coordinates were created using a couple of generators such as Faker, GeoPandas, Pycountry and Natural Earth Data. Please look at Credits, Courtesy and Contributors for details.
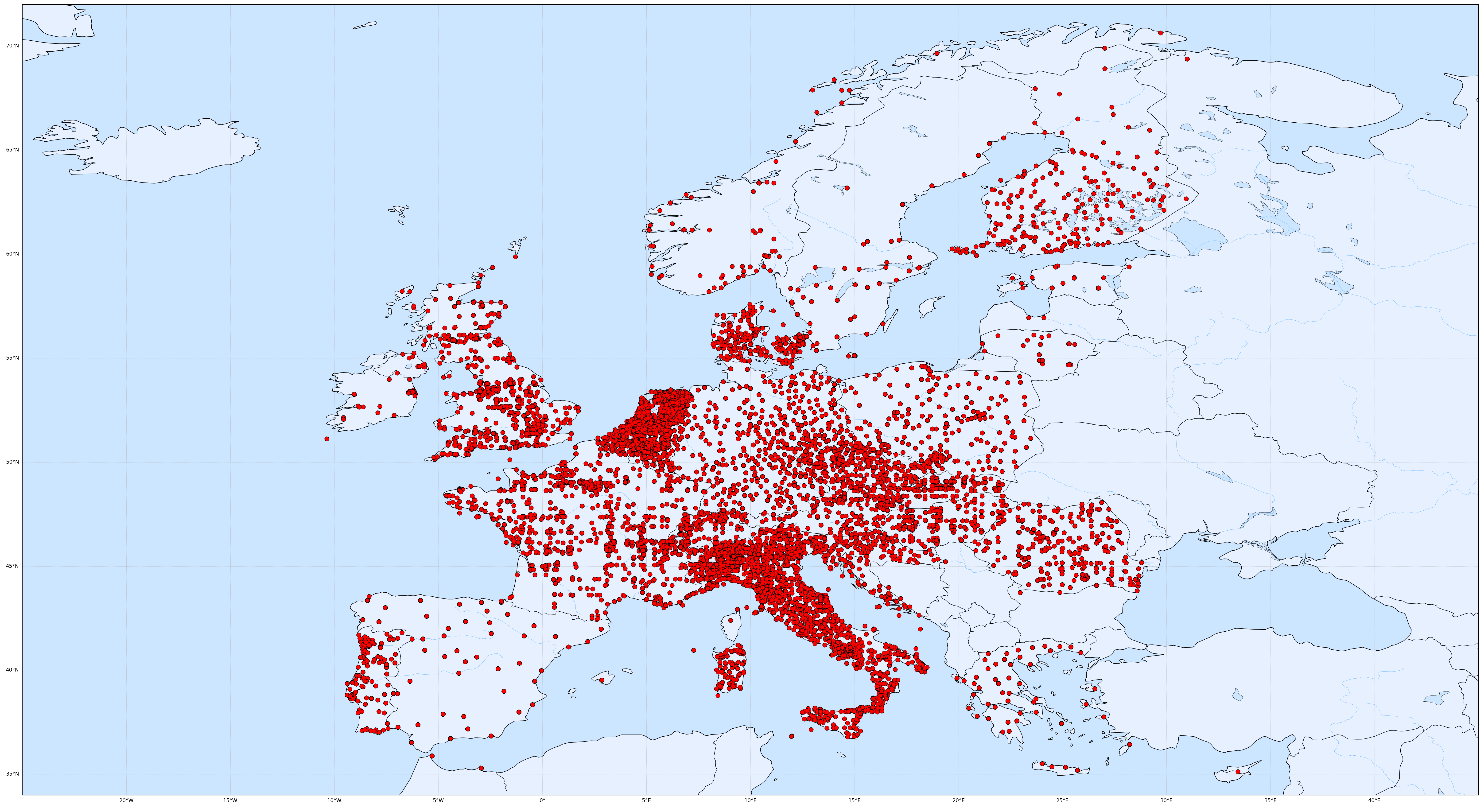 |
|---|
| Figure 1: Geo-Localization of “patients” and “providers” of Synthetic Example Realistic Data. The example data is a randomized amalgamation of synthetic sources, bringing stratification and other statistical methods into play. |
The original idea was born with the 25tipster initiative from 2020 where a start was made to generate 25.000 International Patient Summary (IPS) synthetic data sets. For SYNDERAI a set of more than 30.000 example demographic data sets were compiled. See the table below for an example snapshot of the data.
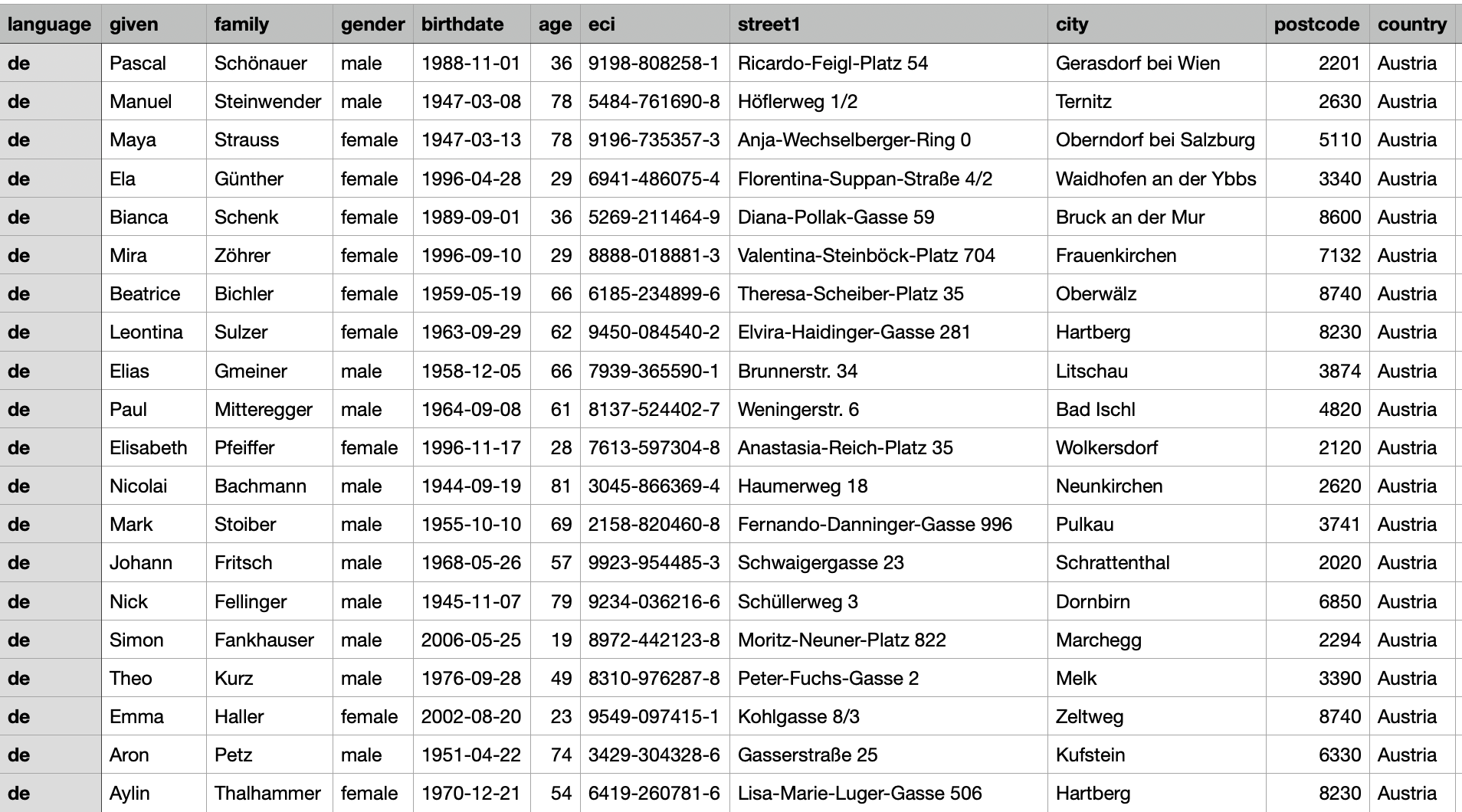
Figure 2: Snapshot of the SYNDERAI generated synthetic demographic data set
Synthea
Synthea from the MITRE Corporation is a well-known and mature synthetic data generator tool. It produces diagnoses, laboratory values, vital signs, immunizations and many more coded data in context. Patients are also included but they are typically US-centric. It also offers a set of international provider data such as hospitals or primary care providers.
For SYNDERAI the approach was chosen to use the Synthea clinical data, and associate the European demographic data with the US-data.
Stratification
For thast purpose, statistical methods also used for clinical trials (stratification [1] of subjects) as well as AI technologies were applied to the two data sets. As stratification factors, gender and (almost same) age were chosen.
| Nationality | Name | Gender | Age |
|---|---|---|---|
| nl | Assen | female | 79 |
| nl | van de Kreeke | female | 55 |
| dk | Møller | male | 81 |
| nl | Goorhuis | male | 82 |
Example data for the stratification strategy to combine different data sets to the SYNDERAI complete synthetic clinical stories
Matching the Synthea clinical part with the European demographic data finally formed the "synthetic foundation" to draw a complete synthetic clinical story for all example artifactcs and for selected personas. With that, multiple cohesive laboratory report sequences, European Patient Summaries and more artifacts could be created.
Providers and Proximity
Synthea also offers a set of international provider data such as hospitals or primary care providers, including their "fake" addresses and geo locations. For matching the EU patients described above with at least a close-by provider, geo-proximity methods were applied to find hospitals or primary care physicians.
Personas
Finally a smaller set of personas were invented based on the described synthetic foundation. In selected cases, stories were defined for Hospital Discharge Reports that were completed by matching data.

Depositphotos.com © Yevhen Shkolenko
Mappings of Coded Concepts
A certain effort was put into mapping coded concepts in the US-centric Synthea data set to coded concepts used in Europe. The mapping was documented in the ART-DECOR® tool and provided as concept maps for the example compiling algorithms.
AI in SYNDERAI
The use of Artificial Intelligence is applied to just fragments and parts of the complete "story", SYNDERAI tells, not to invent whole stories.
For example, the compilation of the EU demographic data set uses AI to better locate and match pure demographic data with geo locations such as addresses etc.
The Laboratory Report is based on realistic lab values and projected on European citzizen/patients all over Europe, stratified [1] by demographic and clinical factors to reach close clinical coverage. Only the normal lab value ranges based on the strata used is provided by concise calls to the AI API. A conclusion is drawn using AI per lab report, based on all prior synthetic lab reports for the respective patient.
Another example is the medication part where an appropriate dosage for a specific medication is proposed by AI. Also the existing Care Plans were complemented by human readable goals based on the coded activities that were generated for many synthetic clinical stories.
The Human Text
Human readable text was also invented, partially with AI assistance, especially for the Hospital Discharge Reports (HDR). In reality, HDR sections typically contain text along with granular data such as codes or measurements for medication, results, diagnoses, etc.
For consistency in the example generating algorithms, a Instance Short Hand (ISH) notation was added to the tooling to allow concise description of instance contents while the actual generation of FHIR examples including identifiers and references used the same mechanisms as for the other artifacts.
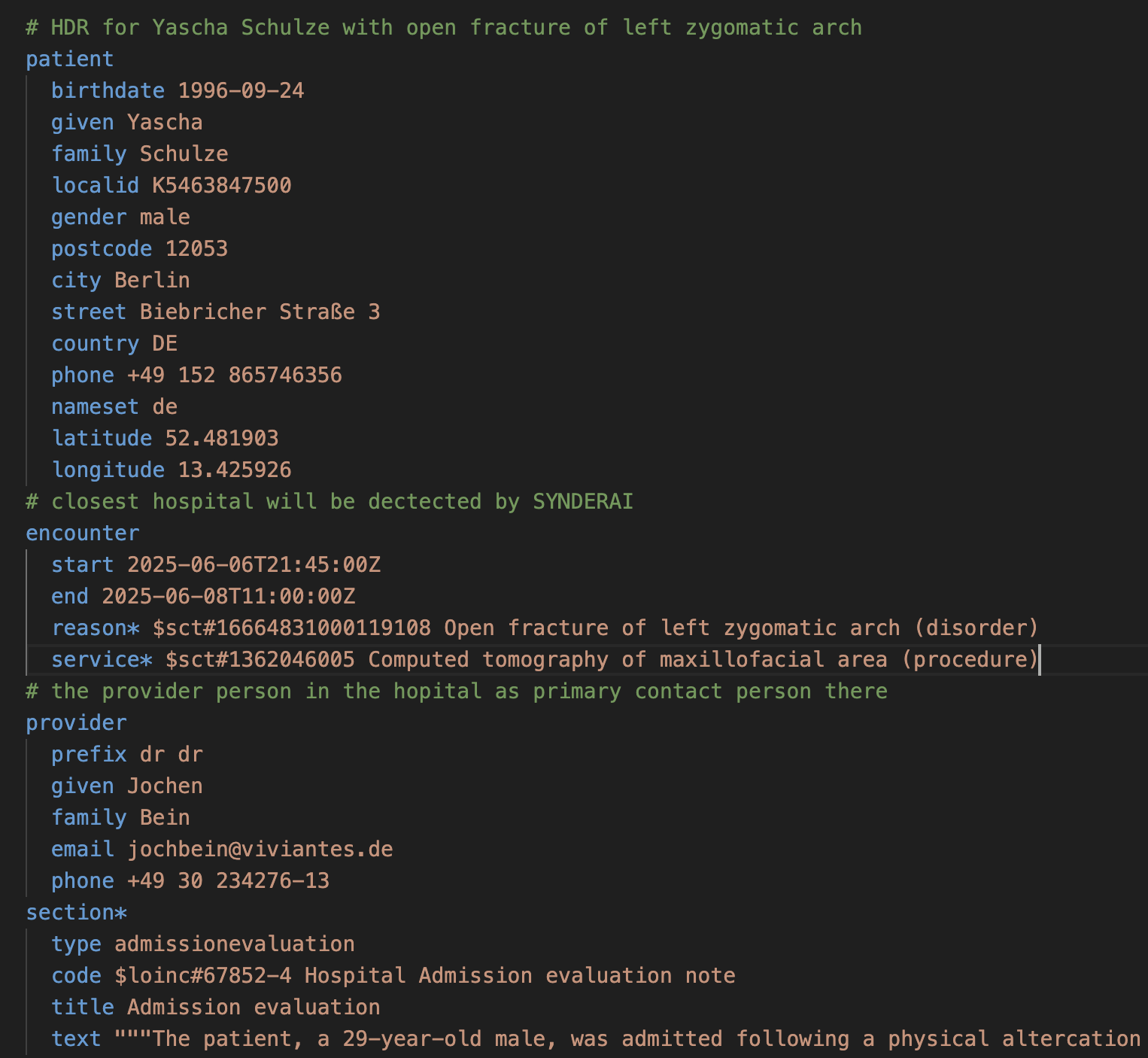
Figure 3: Instance Short Hand example for Yascha Schulze, one of the exposed personas in SYNDERAI.
Process descriptions
The following figure illustrates the architecture of the SYNDERAI example instance generation kernel, a data processing pipeline that takes two synthetic data sources as input and produces FHIR Shorthand (FSH) output through a series of sequential processing steps.
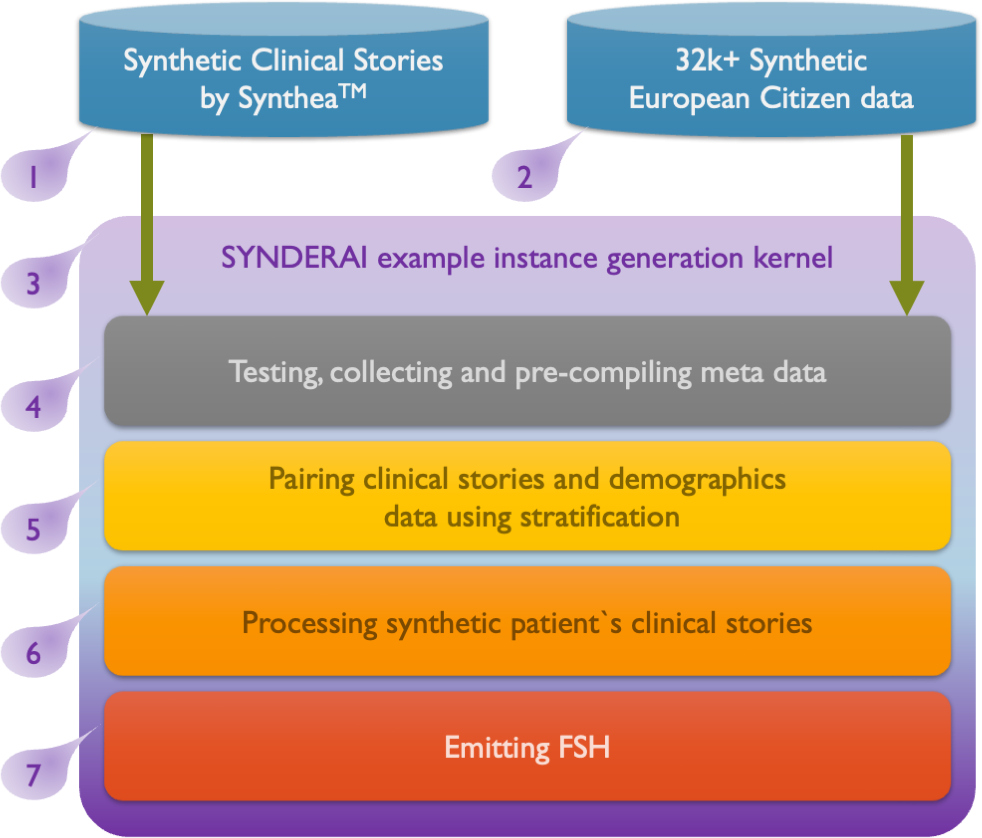
Figure 4: Schematic overview of SYNDERAI input datasets and the internal pipline to generate synthetic example instances in FSH format.
Two data sources feed into the kernel: (1) Synthetic Clinical Stories generated by Synthea by Mitre, and (2) a dataset of 32,000+ Synthetic European Citizen demographic records. Both are represented as database cylinders at the top of the diagram.
Within the kernel, four processing stages are executed in sequence:
- Testing, collecting and pre-compiling meta data (3): an initial quality control and metadata aggregation step applied to the incoming data.
- Pairing clinical stories and demographics data using stratification (4): the clinical narratives from Synthea are matched with the European citizen demographic records using a stratification strategy to ensure representative, realistic pairings.
- Processing synthetic patient's clinical stories (5): the paired data undergoes further processing to refine and structure the synthetic patient records.
- Emitting FSH (6): the final stage outputs the processed synthetic patient data in FHIR Shorthand (FSH) format.
The numbered labels (1–7) along the left margin indicate the sequential flow of the pipeline.
The following figure illustrates the downstream processing pipeline that follows the SYNDERAI example instance generation kernel, depicting how FSH output is compiled into FHIR JSON and validated.
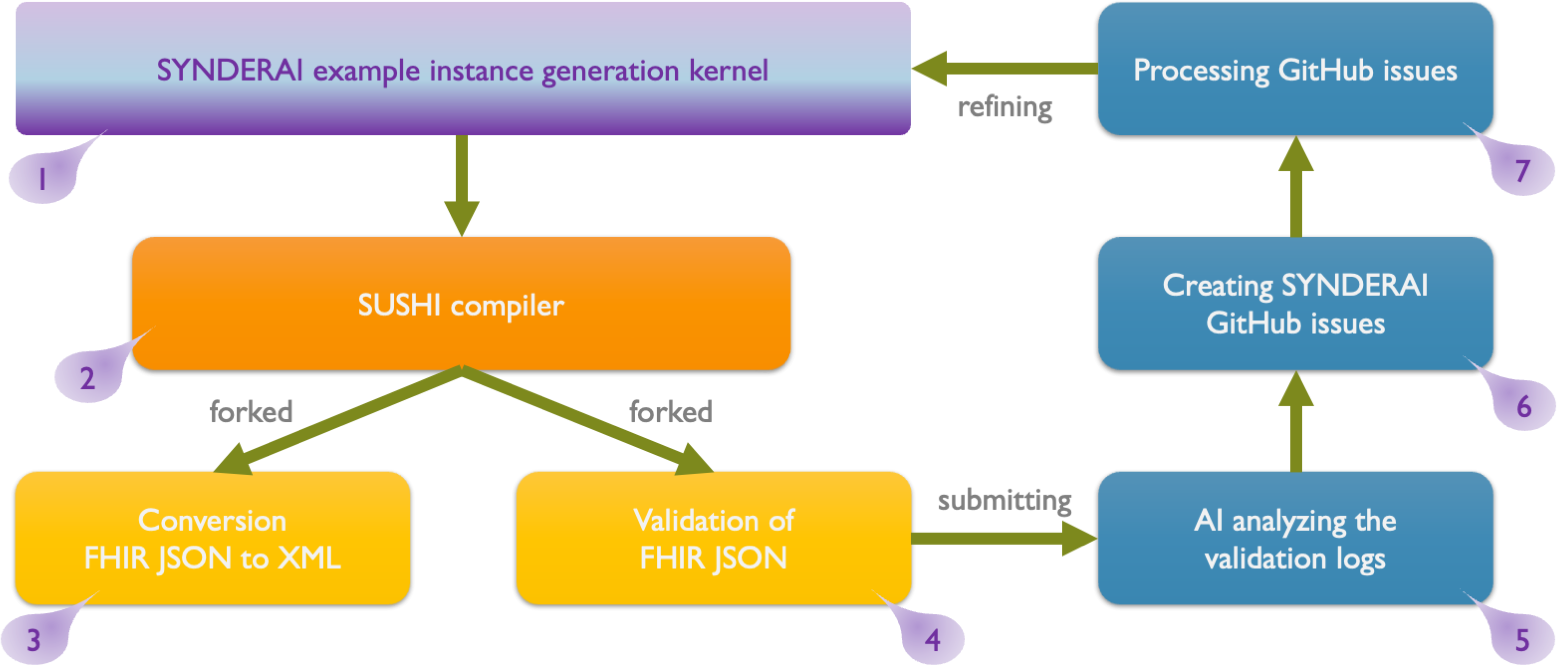
Figure 5: Schematic overview of SYNDERAI's post-processing piplines, including validation (see following chapter).
The pipeline begins at the top left with the SYNDERAI example instance generation kernel (1), whose FSH output flows into the SUSHI compiler (2), which transforms the FSH into the standard FHIR-JSON format. From the SUSHI compiler, the workflow forks into two parallel tracks:
- Conversion of FHIR JSON to FHIR XML (3): The compiled output is converted from FHIR JSON to FHIR XML serialization formats. This is a necessary step to complete the set of instances for simpler vizualisation using the vi7eti methodology.
- Validation of FHIR JSON (4): The FHIR JSON output is independently validated to check conformance and correctness.
The validation output (4) is submitted to AI analyzing the validation logs component (5) on the right side of the diagram. The AI analysis then feeds SYNDERAI GitHub Issues (6), where identified problems are logged as issues. These GitHub issues are the resolved (by human interaction) and subsequently used to refine the SYNDERAI kernel (7), closing a feedback loop back to phase 1.
Finally, both parallel tracks (3 and 4 in the following figure) converge at a synchronization point — waiting for semaphore processes to finish (5) — which ensures both forked processes complete before proceeding. Once complete, results are published to SYNDERAI and vi7eti (Stage 9).
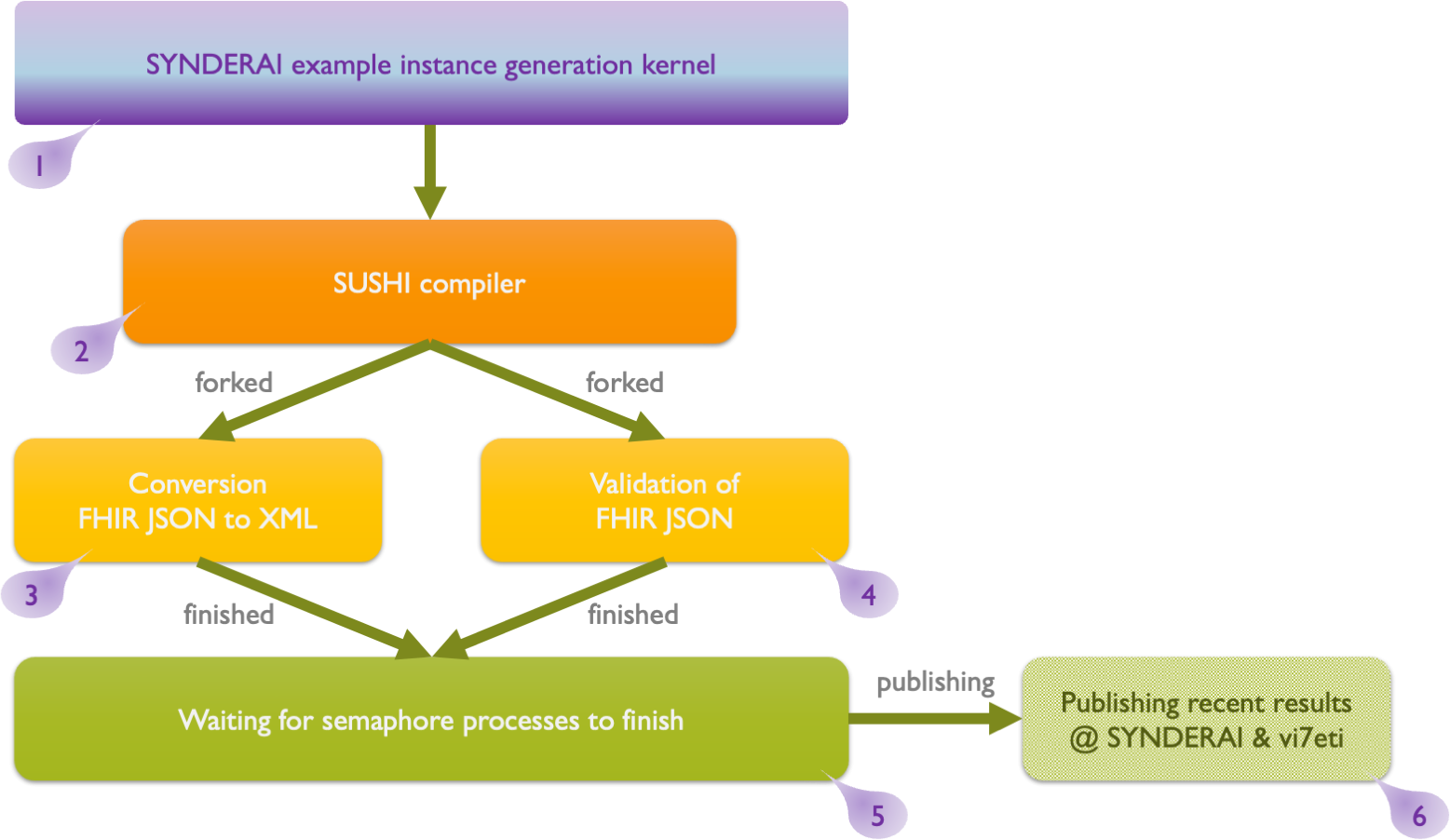
Figure 6: Schematic overview of SYNDERAI's final steps until publication.
The Validation Marathon
In March 2026 efforts were intensified to create formally valid and specification-conformant synthetic examples. The big validation "marathon" was started to process all synthetic examples by FHIR validator(s) aiming on passing (virtually) all examples with no errors.
Everybody who once did FHIR validation of example instances knows who time consuming and nerve-wrecking this task could be. The generation starts with the SYNDERAI example instance generation kernel script. Since the beginning this main script did all processing: Testing, collecting and pre-compiling meta data, Pairing example data, getting clinical data, emitting FSH (see also figures above). Finally the script initiated the post processing cascade: creating FHIR from FSH and copy results.
This included copying all example Bundles to the recent results folder for further processing and then the use of the SUSHI compiler to convert the FSH into FHIR JSON instances first. Subsequently a batch process is forked to run converting the FHIR JSON in the corresponding XML representation in the background.
At the same time another batch process was forked to use the HAPI validator to validate all generated instances.
The resulting validation report is not only inspected "manually" but also an AI pipeline using Large Language Models (LLMs) was set up to analyze the validation report, categorize the error messages and prepare and emit GitHub issues that went directly into the SYNERAI GitHub. From there "humans" could inspect and pick up the problems and fix the SYNDERAI example instance generation kernel script.
It can be assumed that without the help of LLMs this task would have taken much more hours and days (and weeks) than it actually did. The effort was finalized right before the EHDS Plugathon during the IHE Connectathon week in Brussels end of March 2026.
Since April 2026 SYNDERAI collaborates with MedVenture to allow quicker and continuous validation. A report on the achievements is in preparation.
Moving example data towards European Population
Analyzing the list of conditions and their frequency generated by Synthea from Mitre that SYNDERAI used from July 2025 on to create the first set of Synthtic data (Packages version 1.0+ and 2.0+), we can observe that the distribution is not comaprable to typical population based diseases.
The data generation processes needed to reflect public health conditions of populations in Europe much better than the synthetic data funds used until April 2026. The updated funds used from May/June 2026 on are reflected in SYNDEAI packages version 3.0+. Please read here about the achievements and the whole story behind the lengthy adaptation process.
Synthetic Data FHIR Packages
SYNDERAI are published now as Synthetic Data FHIR Packages to be downloadable from usual sources.
[1] Stratification of clinical trials is the partitioning of subjects and results by a factor other than the treatment given. – see Wikipedia https://en.wikipedia.org/wiki/Stratification_(clinical_trials)